
Do tej pory udało się nam osiągnąć coś bardzo ważnego: uzyskać dane. Nie jest dla nas istotne jak tego dokonaliśmy, najważniejsze, że jesteśmy w ich posiadaniu. Aby móc z nich skorzystać musimy jednak wcześniej przygotować do analizy. Zdarza się często, że jakość danych pozostawia wiele do życzenia. Trzeba sobie zdawać sprawę, że zwłaszcza w przypadku danych publicznych, instytucje, które gromadzą dane, nie robią tego, aby można było na ich podstawie prowadzić jakieś analizy, dane gromadzone są często po prostu do celów administracyjnych, biurokratycznych. Dlatego też urzędnicy niespecjalnie przywiązują uwagi do jakiejkolwiek standaryzacji prezentacji danych. Mając jednak dane w postaci tabelarycznej w takich formatach jak csv czy xls, możemy je odpowiednio sformatować, posortować i przefiltrować. Pomoże nam w tym program Open Refine, który dzięki automatyzacji znacząco przyspieszy naszą pracę.
Przygotuj dane z Open Refine
Open Refine (do 2012 funkcjonowało jako Google Refine) to narzędzie ułatwiające porządkowanie i przetwarzanie danych. Aplikacja umożliwia import danych z wielu formatów: TSV, CSV, *SV, .xls i .xlsx, JSON, XML, RDF/XML. Open Refine ułatwia sortowanie i dzielenie danych, a także ich przetwarzanie z wykorzystaniem tzw. wyrażeń regularnych. Swoją pracę można w łatwy sposób eksportować do popularnych formatów (csv, tabela html czy pliki Excela i ODT). Z Open Refine korzystać można w systemach linuksowych, OS oraz w Windowsach. Narzędzie korzysta oraz dystrybuowane jest na licencjach Open Source.
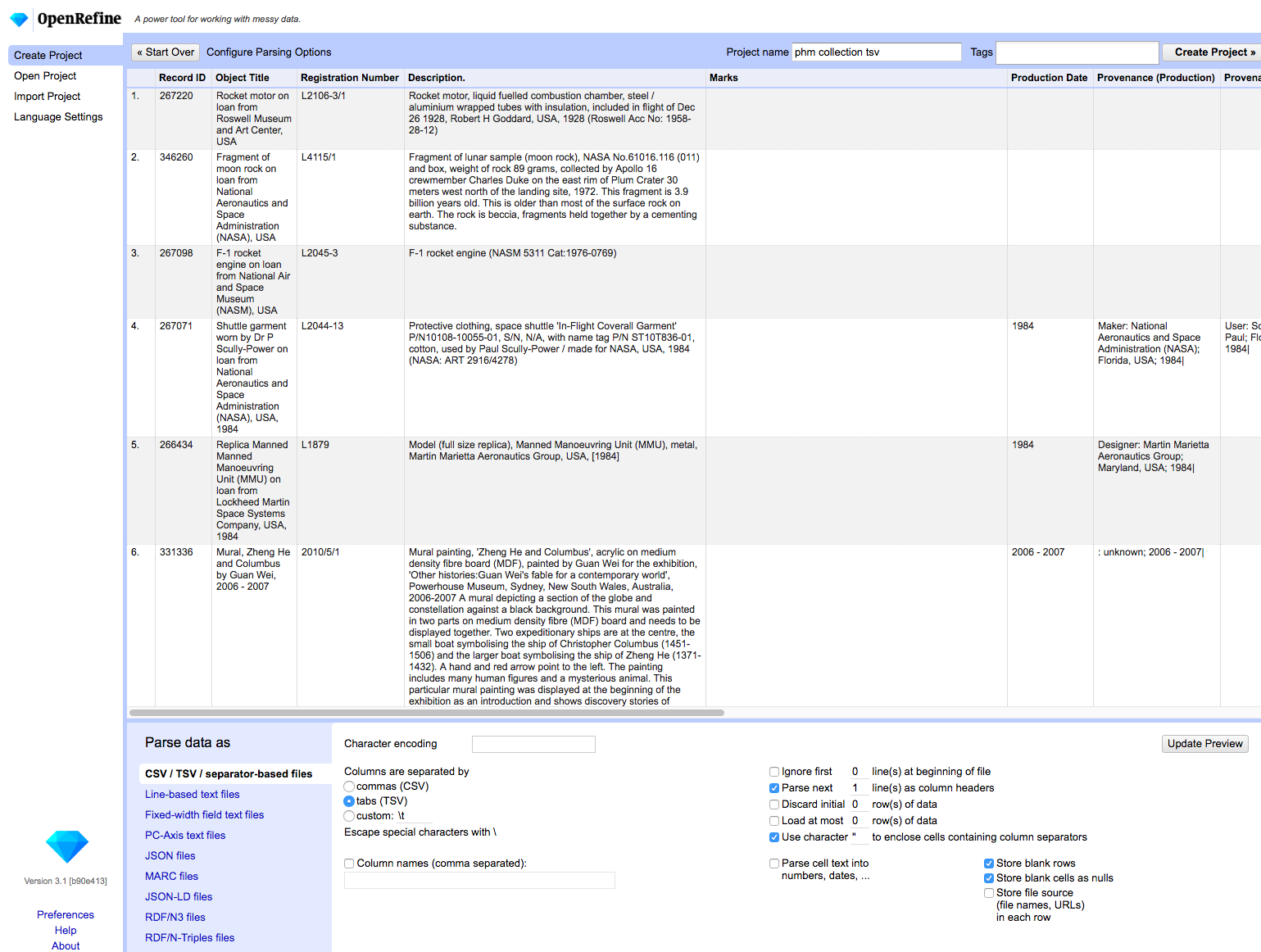
Narzędzie pobierzemy ze strony http://openrefine.org/. Aby je zainstalować, trzeba postępować zgodnie z zamieszczonymi instrukcjami. Aplikacji używamy w przeglądarce. Aby rozpocząć pracę z plikiem z danymi, musimy kliknąć w “Create project”, a następnie skorzystać z możliwości narzędzia i wybrać sposób pobrania danych. Oprócz tradycyjnego pobrania pliku z komputera, możemy także umieścić link do adresu url czy bezpośrednio połączyć program z arkuszem google. W aplikacji pojawi się nasza tabela, zaś na dole dodatkowe możliwości przetworzenia naszej tabeli.
Kliknij, aby powiększyć obraz
Program domyślnie pierwszy wiersz ustawi jako nagłówek. Możemy także ustawić sposób parsowania naszego pliku, np. w przypadku tsv separacja komórek powinna być zastosowana za pomocą tabulatorów, w przypadku csv za pomocą przecinków. Program zazwyczaj wszystkie te informacje wykrywa i automatycznie nam w tym pomaga, poprzez ten dolny panel możemy jednak dokonać manualnie kilku zmian w sposobie pobrania naszej tabeli. Gdy udało się nam już zaimportować naszą tabelę, możemy sobie przeklikać różne miejsca, aby bliżej zapoznać się z interfejsem. Do manipulowania danymi służą funkcje dostępne poprzez kliknięcie w ikonkę trójkąta przy nagłówkach kolumn. Daną kolumnę np. możemy zwinąć klikając w “view” i dalej w “Collapse this column”, jeżeli chcemy, aby kolumna z powrotem się pojawiła, wystarczy kliknąć w puste miejsce po kolumnie. Kolumny możemy też przesuwać w prawo lub lewo tak, aby wygodniej się nam na nich pracowało. Możemy także zmieniać nazwy kolumn poprzez funkcję “rename”. Na bocznym panelu z lewej strony możme prześledzić historię naszych zmian i powrócić np. do wcześniejszych ustawień. Po zakończeniu pracy nasz projekt możemy wyeksportować do różnych formatów jak csv, tsv, xls, xlsx czy tabela w dokumencie html. Jeżeli pracujemy z bardzo dużymi zbiorami danych, możemy zwiększyć alokację zużywania pamięcie dla naszej aplikacji. Możemy to zrobić zgodnie z instrukcją: https://github.com/OpenRefine/OpenRefine/wiki/FAQ%3A-Allocate-More-Memory
Przetwarzanie i czyszczenie danych
Poznaliśmy już dokładniej interfejs Open Refine, teraz czas na zapoznanie się z funkcjonalnością tego narzędzia. Dla pokazania możliwości programu wykorzystamy zbiór danych ze strony dane.gov.pl https://dane.gov.pl/dataset/1176 zawierający listę beneficjentów (projektów) Funduszy Europejskich w latach 2014-2020.
Sortowanie
Dane z naszej tabeli możemy posortować co może przydać się nam do późniejszej analizy. Do tego wykorzystamy funkcję “sort”, która jak już wcześniej wspomnieliśmy, pojawi się po kliknięciu w ikonę trójkąta przy nazwie kolumny. Daną kolumnę możemy posortować ze względu na tekst (od a do z lub na odwrót), liczby (od najmniejszych do największych lub na odwrót), daty (od najwcześniejszych lub najpóźniejszych), i format “Booleans”, czyli dane, które mają wartość prawdy lub fałszu. Metodą drag&drop możemy ustalić w jakiej kolejności mają pojawić się np. puste komórki lub te z błędem.
Wyszukiwanie fasetowe
Open Refine daje nam możliwość analizy każdej kolumny np. pod względem powtarzanych cech w wierszach. Możliwości wyszukiwania fasetowego to przede wszystkim sposobność na spojrzenie na nasze dane z różnego punktu widzenia. Metoda ta nie zmienia wartości komórek. Spróbujmy zatem tej metody na kolumnie “Nazwa beneficjenta”. Wybieramy “facet” i następnie “Text facet”. Na lewym panelu pojawia się efekt funkcji. Zmieńmy “Sort by” na “count”. Jak widzimy, na pierwszym miejscu jest Miasto Łódź, które otrzymało fundusze na 121 projektów. Widzimy także “21497 choices”, czyli oznacza to, że łącznie 21497 podmiotów uzyskało dofinansowanie na swoje projekty. Funkcję tę można zastosować także do wartości liczbowych. Aby jednak tego dokonać musimy się na moment zagłębić w inną możliwość narzędzia. Zwróćmy uwagę na kolumnę “Poziom unijnego dofinansowania w procentach”. Wartości zapisane są z przecinkiem, oznacza to, że nie są one liczbami. Cyfry dziesiętne w programie Open Refine oddzielane są kropką. W naszym przypadku są to przecinki, więc oznacza to, że wartości w tej kolumnie to tekst. Aby wykorzystać funkcję do wyszukiwania fasetowego na liczbach, musimy wartości z tej kolumny przekonwertować na wartość liczbową.
W Open Refine mamy do czynienia z 4 typami danych: tekst (string), liczba (integer), boolean (wartość prawda lub fałsz), data. Każda komórka zawierająca jakieś wartość musi być jednym z tych czterech typów danych. W celu analizy danych możemy dokonać transformacji jednego typu na inny.
Aby przekonwertować wartość tekstową na liczbową, musimy najpierw zamienić przecinek na kropkę i następnie dokonać transformacji. Do tego użyjemy zaawansowanej możliwości tworzenia tzw. wyrażeń regularnych przy pomocy Google Refine Expression Language, czyli GREL. GREL działa tak samo jak tworzenie formuł w Excelu. Klikamy więc w ikonę trójkąta naszej kolumny, potem “Edit cells” i wybieramy Transform. W ramce, gdzie zapisana jest nazwa “value” musimy wpisać następującą regułę: value.replace(‚,’,’.’).toNumber()
value.replace(‚,’,’.’) – oznacza, że w wartości komórki (value) odnajdujemy przecinek (pierwszy znak w apostrofie – ‘,’) zastępujemy kropką (drugi znak w apostrofie ‘.’). Przecinek i kropka w apostrofach oddzielone są przecinkiem.
toNumber() – dokonujemy transformacji wartości (value) na typ liczbowy (number).
Klikamy “ok” i, jak widać, nasze wartości zmieniły kolor na zielony. Oznacza to, że są teraz typem liczbowym.
Możemy teraz skorzystać z funkcji fasetowej. Klikamy w “facet” i następnie w “numeric facet”. W lewym panelu pojawiła się ramka z grafiką.

Kliknij, aby powiększyć obraz
Suwakiem możemy np. ustawić obszar 40% dotacji. Możemy teraz dodać kolejny “facet” z nazwami beneficjentów. Klikamy przy kolumnie z nazwami beneficjentów “facet” i “text facet”. W ten spobób na lewym panelu mamy listę podmiotów, które otrzymały dotacje na poziomie 40% wartości projektu.
Wykrywanie duplikatów
W zbiorach danych często mamy do czynienia z powtarzającymi się rekordami. Duplikaty to rekordy, które pojawiają się minimum podwójnie. W tym fragmencie posłużymy się przykładem z zagranicznej bazy danych, a konkretnie z The Museum of Applied Arts and Sciences z Sydney. Skorzystamy z bazy danych z tamtejszych zbiorów. Obecnie muzeum dostęp do swych zbiorów umożliwia przez API. My jednak skorzystamy z pliku .tsv, który wcześniej został pobrany z API jako plik JSON. Plik można pobrać pod tym linkiem:
Plik uploadujemy w podany wcześniej sposób. Aby sprawdzić liczbę zduplikowanych rekordów posłużymy się w tej bazie polem “Registration Number”. Następnie wybieramy Facet -> Customized facets -> Duplicates facet. Jak widzimy w bocznym panelu z wartością “true” znajdujemy 667 rekordów. To oznacza, że 667 rekordów bazy danych jest zduplikowanych. Klikając w “true” w kolumnie Registration Number” zauważymy na górze puste pola. Oznacza to, że jako zduplikowane pola program bierze też pod uwagę puste pola. Musimy je więc także wyodrębnić. Klikamy więc Registration Number -> Facet -> Customized facets -> Facet by blank. Zaznaczając “false” widzimy, że teraz rekordów zduplikowanych jest 37. Aby przyjrzeć się tym rekordom wybierzmy dodatkowo “text facet”. Posortujmy teraz te rekordy przez liczbę (“count”). Zobaczymy, że na pierwszym miejscu znalazł się rekord, który ma nawet 4 duplikaty. Następnie spróbujemy nieco inną metodą sprawdzić duplikaty w kolumnie Record ID. Jako, że fasetowe wyszukiwanie duplikatów nie przeszukuje wartości liczbowych (integers), zaczniemy od posortowania tej kolumny. Wybieramy “Sort by” na pasku nad nagłówkami kolumn i dalej “By Rekord ID”, zaznaczamy “numbers” i wybieramy “smallest first”. Podczas sortowania należy też zaznaczyć “Reorder rows permanently”, aby zmiany w sortowaniu zostały zapisane na trwałe. Jak usunąć duplikaty dowiemy się w następnych częściach lekcji.
Zastosowanie filtru tekstowego
Skupmy się na wcześniejszej bazie danych. Spróbujmy znaleźć w zbiorach muzeum jakieś rekordy, które mogą dotyczyć naszego kraju. Sprawdźmy tytuły prac. Wybieramy “Object Title“, a następnie “Text filter”. W bocznym panelu wpiszmy “Poland”. Brawo, znaleźliśmy 7 rekordów. Filtrem tekstowym możemy teraz sprawdzić kolumnę kategorii zbioru dzieł. Wybierając kolumnę “Categories” i “Text filter” wpiszmy “|”, w ten sposób sprawdzimy rekordy, które dotyczą więcej niż jednej kategorii. Jak widzimy, większość naszych rekordów dotyczy więcej niż jednej kategorii. Wpiszmy teraz podwójny podzielnik “||”. Jak widzimy, mamy 8 rekordów z błędnie wpisanymi podziałami kategorii. Dzięki filtrowaniu tekstowemu nie tylko możemy wyszukać różnego rodzaju dane, ale także wykryć nieprawidłowości.
Transformacje komórek
Oprócz filtrowania i analizy naszego zbioru danych, Open Refine pozwala nam także na tranformacje i edycję komórek. W programie umożliwia to zakładka “Edit cells”. Czasami musimy np. “oczyścić” wartości w komórkach, połączyć je czy usunąć niepotrzebne spacje etc.
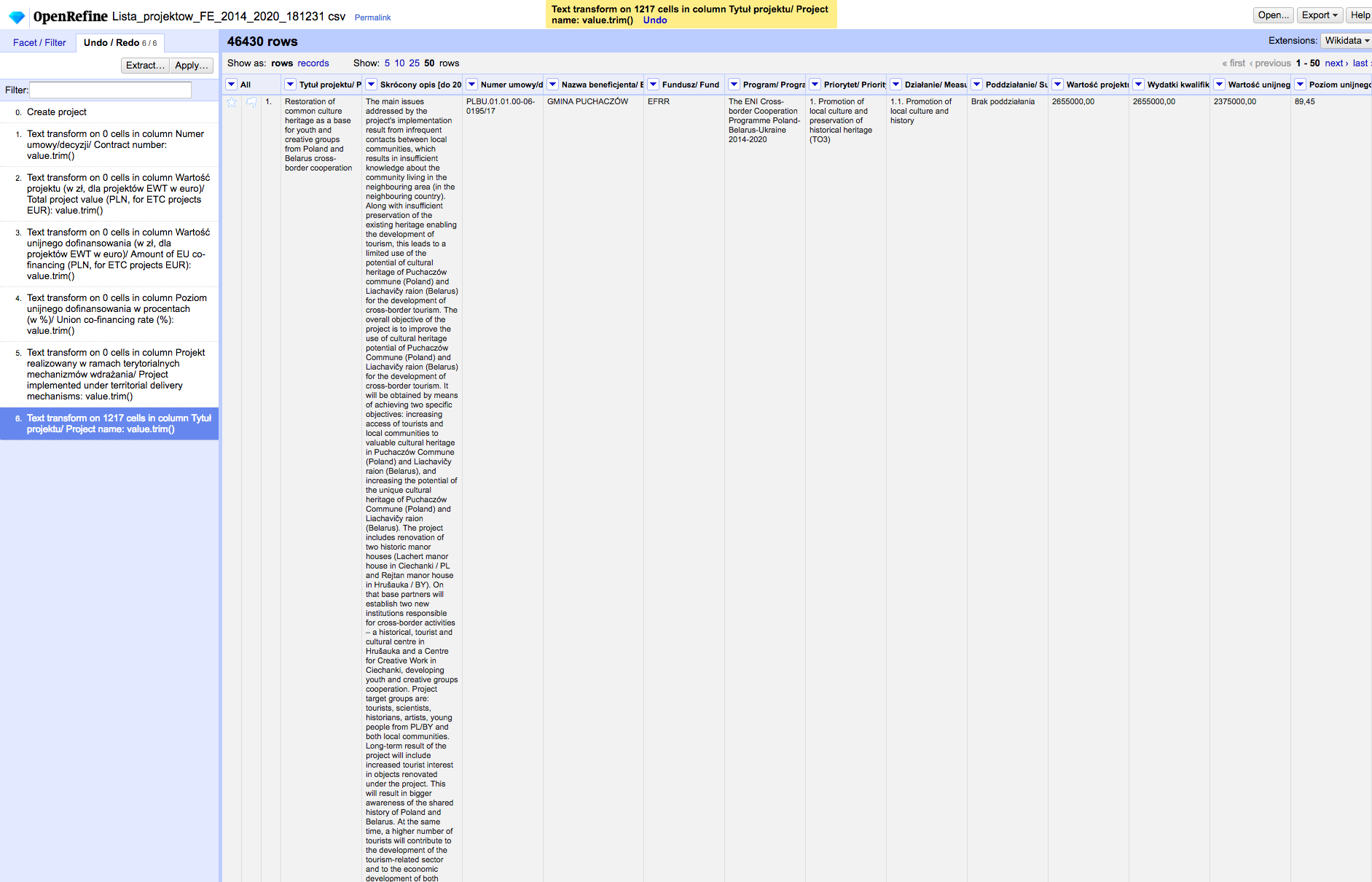
Transformacje możemy rozpocząć od usuwania białych znaków (np. niepotrzebnych spacji znajdujących się na początku lub na końcu wartości komórek). Sprawdźmy więc tym razem w naszej bazie dotacji unijnych kolumnę z tytułami projektów. Aby wykryć białe znaki, postępujemy kolejno: Tytuł projektu -> Edit cells -> Common transforms -> Trim leading and trailing whitespace. Jak widzimy białe znaki usunięto w 1217 komórkach.
Kliknij, aby powiększyć obraz
Dodać należy, że tego typu operacje przeprowadzamy tylko na typach tekstowych, czyli string, a nie numerycznych, czyli integer. Można także skorzystać z metody “Collapse consecutive whitespace”, która usuwa białe znaki ze środka stringów.
W trakcie nauki Open Refine mogliście zapoznać się z działaniem tzw. wyrażeń regularnych. Tak się składa, że aby dokonać transformacji komórek wszystkich kolumn naszej bazy trzeba skorzystać właśnie z wyrażeń regularnych. Z GREL skorzystamy klikając w nagłówek pierwszej kolumny bazy “All”.
Twoje zadanie:
Przy pomocy wyrażeń regularnych usuń we wszystkich komórkach spacje znajdujące się przed przecinkami.
+ zobacz odpowiedź
Jeżeli twoja baza oparta jest na danych pochodzących ze strony internetowej, może się zdarzyć, że komórki mogą zawierać pozostałości kodu html. Np. litera “ś” w kodzie html zapisywana jest jako “ś”. jeżeli odnajdziesz w swojej bazie jakieś komórki, w których treść rozpoczyna się od “&” i kończy się średnikiem “;”, możesz zmienić sposób wyświetlania takich znaków na czytelny. Zrobisz to klikając w danej kolumnie Edit cells -> Common transforms -> Unescape HTML entities. W naszej bazie dotacji unijnych możemy sprawdzić w ten sposób kolumnę “Skrócony opis”. Okazuje się, że program zamienił 466 komórek, wykrywając m.in. takie znaki jak cudzysłów, który wcześniej był zapisany w formie kodu html “””
Kolejną możliwość jaką dają nam transformacie jest zmiana wielkości liter w komórkach tekstowych np. z małych na duże i odwrotnie. Aby zmienić tekst komórki na duże litery klikamy w daną kolumnę Edit cells -> Common transforms -> To uppercase. Wykorzystanie odpowiednich metod zależy od tego jak chcemy przekształcić teksty w odpowiednich kolumnach.
Więcej możliwości pracy w edycji komórek daje z pewnością wykorzystanie wyrażeń regularnych. Jeżeli rozpoczniesz pracę z Open Refine zachęcamy do zapoznania się możliwościami jakie daje wykorzystanie właśnie wyrażeń regularnych. Więcej informacji na temat General Refine Expression Language znajdziesz pod tym linkiem na serwisie github.com https://github.com/OpenRefine/OpenRefine/wiki/General-Refine-Expression-Language
Usuwanie niewłaściwych danych
We wcześniejszych częściach lekcji dowiedzieliśmy się jak filtrować dane i jak jak wykorzystać wyszukiwanie fasetowe. Wykrycie duplikatów i powtarzających się elementów w treści komórek do dopiero część naszej pracy. Następnie powinniśmy pozbyć się tych niepotrzebnych komórek. Właściwie tutaj zaczyna się to, co nazywamy czyszczeniem danych, czyli usunięcie konkretnych komórek z naszej bazy danych. Pamiętaj, że usuwanie komórek powinno się odbywać po uprzednim wykorzystaniu metod “facet” i filtrów, w przeciwnym razie narazisz się na usunięcie wszystkich komórek. Wróćmy teraz do naszej wcześniejszej bazy muzeum z Sydney i wykonajmy te same kroki, które przeszliśmy już we wcześniejszych częściach lekcji.
W kolumnie “Registration Number” wybieramy Facet -> Customized facets -> Duplicates facet. Jak widzimy w bocznym panelu z wartością “true” znajdujemy 667 rekordów. Jak już wiemy, wśród tych rekordów znajdują się także puste pola, których jednak nie chcemy się pozbyć. Musimy je więc także wyodrębnić. Klikamy więc Registration Number -> Facet -> Customized facets -> Facet by blank. Zaznaczając “false” widzimy, że teraz rekordów zduplikowanych jest 37. Nadszedł czas, aby je usunąć. W nagłówku pierwszej kolumny “All” klikamy Edit rows -> Remove all matching rows. Jak widzimy w komunikacie, właśnie usunęliśmy 37 wierszy.
Grupowanie danych, czyli klastrowanie
W ostatnim przykładzie zajmiemy się problemem, który często pojawia się w bazach danych, zwłaszcza gdy mamy do czynienia z danymi publicznymi. Tego typu bazy zazwyczaj są zbierane przez wiele osób, dlatego często można spotkać różne nazwy dotyczące tych samych elementów. Np. w kategoriach wydatków możemy natknąć się na “Wydatki na usługi zdrowotne | zdrowie”, “Wydatki na usługi zdrowotne | Zdrowie” i “Wydatki na zdrowie”. Jak można się domyśleć, wszystkie dane objęte tymi kategoriami dotyczą tego samego rodzaju wydatku. Problem ten rozwiązuje tzw. klastrowanie. To nic innego jak grupowanie obiektów o podobnych właściwościach. Program Open Refine daje nam możliwość automatycznego poradzenia sobie z problemem grupowania. Skorzystajmy teraz z bazy muzeum z Sydney. Aby sprawdzić, czy taka sytuacja występuje w naszej bazie, sprawdźmy kolumnę kategorii dzieł. Do klastrowania kolumny wykorzystamy metodę “cluster”. Znajdziemy ją w Edit cells -> Cluster and edit. Następnie naszym oczom ukaże się panel z pogrupowanymi kategoriami. Program Open Refine stosuje algorytmy skonstruowane z wielu metod pozwalających wykryć podobieństwa w odpowiednich kategoriach.

Kliknij, aby powiększyć obraz
Przeanalizujmy tę ramkę. Cluster Size oznacza ile różnych oznaczeń tych samych kategorii program znalazł. Row Count pokazuje ile wierszy znaleziono z wszystkimi nazwami kategorii. W Values in Cluster wypisane są wykryte przez program rodzaje kategorii (w naszym przypadku program wykrył po dwa rodzaje oznaczeń tej samej kategorii dla wszystkich kategorii). W polu “Merge” możemy zaznaczyć checkbox, wówczas nazwy kategorii zmienią się w treść znajdującą się w “New Cell Value”. Następnie wybieramy “Merge Selected & Re-Cluster” (jeżeli nie chcemy zamykać okna i np. przyjrzeć się jeszcze raz możliwości klastrowania) lub “Merge & Close” (jeżeli chcemy dokonać klastrowania i zamknąć okno). Przy grupowaniu podobnych elementów powinniśmy działać ostrożnie, aby się nie okazało, że połączyliśmy dwa zupełnie różne obiekty.
Program Open Refine z pewnością daje duże możliwości w czyszczeniu danych, jego wielką zaletą jest fakt, że jest darmowy. Program można rozwijać dodając do niego kolejne rozszerzenia lub też w przypadku wyrażeń regularnych zastosować język programowania. Swoje umiejętności z wykorzystywania tej aplikacji można poszerzać na stronie programu na serwisie github.com – https://github.com/OpenRefine/OpenRefine/wiki/Documentation-For-Users oraz na oficjalnej stronie http://openrefine.org/ , gdzie znajdziemy także materiały wideo. Wyczyszczone bazy danych możemy następnie wykorzystać do agregacji i wstępnych wizualizacji.
