
Czym jest internet i jak działa?
Na początku tej części kursu skupimy się na zasadach działania internetu. Wiedza ta z pewnością przyda się do zwiększenia świadomości poruszania się w świecie cyfrowego dziennikarstwa. W dzisiejszych czasach bowiem większość danych znajdziemy w internecie na samych stronach internetowych czy zamieszczonych na nich plikach. Internet to nic innego jak pajęczyna połączeń pomiędzy komputerami/serwerami komunikująca się przy pomocy ustalonego protokołu. W tym momencie nie będziemy podejmować zagadnień związanych z tym, jak od środka funkcjonuje sieć internet (jeżeli interesują Cię te zagadnienia, odsyłamy do książek lub wielu materiałów dostępnych online). To, co musimy wiedzieć to fakt, że każda strona internetowa, aby była dostępna, musi być hostowana na jakimś serwerze. Obecnie komunikując się przez internet, komunikujemy się przede wszystkim poprzez przeglądarkę internetową. Przeglądarka stanowi dla nas okno na świat internetu. Przeglądarka to nic innego jak program, który analizuje kod źródłowy strony internetowej i wyświetla go zgodnie z ustalonymi standardami. Dzięki czemu przez przeglądarkę możemy mieć dostęp właśnie do kodu źródłowego strony internetowej. Jak to działa? Przeglądarka internetowa, nazywana klientem wysyła żądanie do serwera. Ten wysyła odpowiednie pliki do przeglądarki. Klient (przeglądarka) interpretuje kod przesłany w pliku i wyświetla go na ekranie. Za każdym razem klikając w jakiś link/element na stronie internetowej wymuszamy na przeglądarce, aby wysłała odpowiednie żądanie do serwera (np. wyświetlenie następnej strony czy rozwinięcie artykułu). To w jaki sposób komunikuje się serwer z klientem określa protokół HTTP (widoczny na pasku adresu URL). Komunikacja ta oparta jest na wspomnianych już żądaniach i odpowiedziach. Wiedza o tym, jak funkcjonuje protokół HTTP przyda się przy korzystaniu z API w pobieraniu danych.
Strony internetowy: jak działają?
Strona internetowa to nic innego jak kolejny plik zapisany w swoim specyficznym języku. Może nie zdajesz sobie z tego sprawy, ale swoją stronę internetową możesz stworzyć w pięć minut w tak nieskomplikowanym programie jak notatnik. Do wyświetlania i przeglądania stron internetowych potrzebujemy jednak dodatkowego narzędzia: jest nim przeglądarka internetowa.
Pierwsza strona internetowa, która powstała w 1990 roku, wyglądała następująco
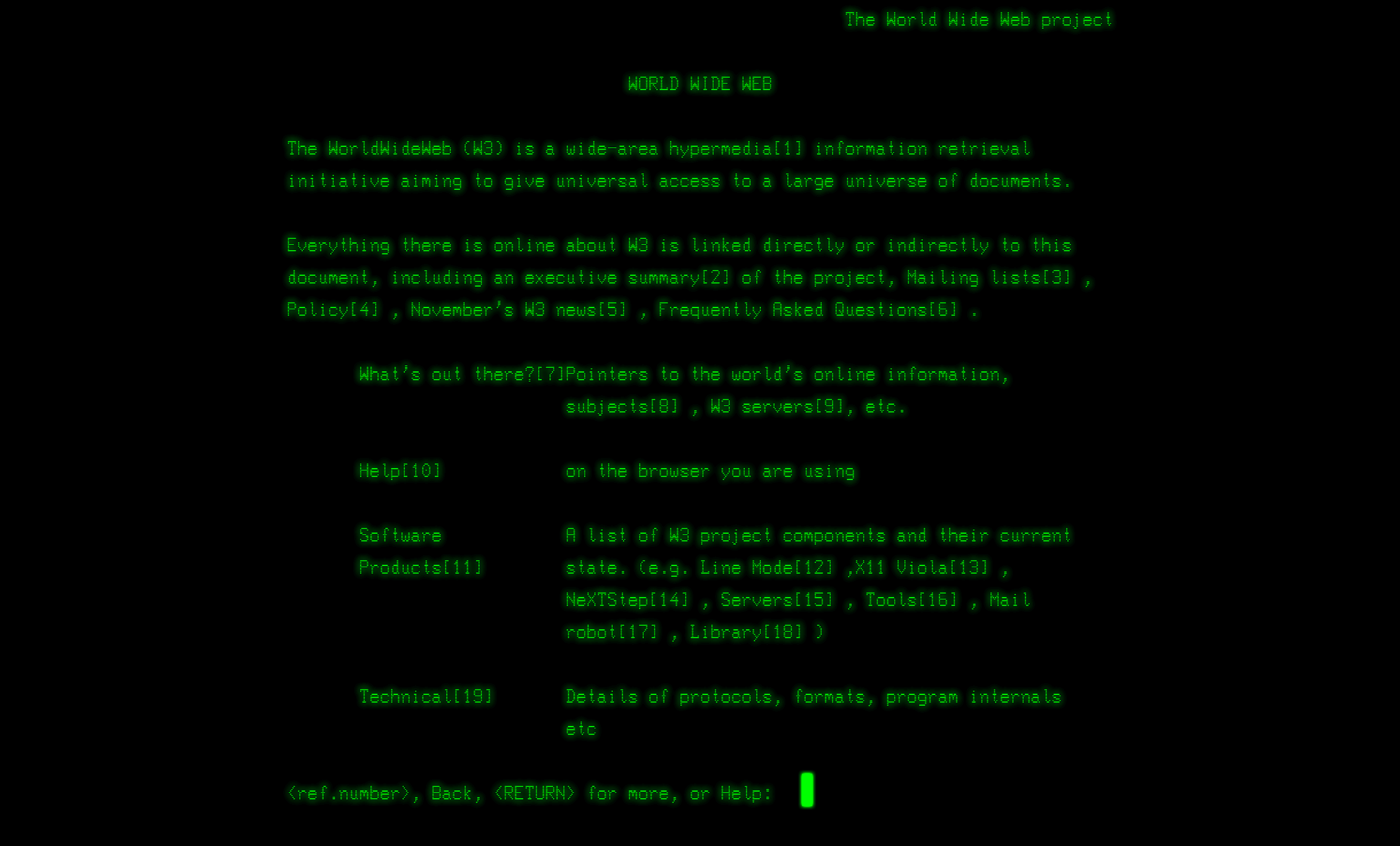
Jak widać, pierwsze strony internetowe zupełnie nie przypominały tych obecnych. Tzw. GUI, czyli graficzny interfejs użytkownika praktycznie nie istniał. Strona internetowa komunikowała się przede wszystkim tekstem. W ciągu kilkudziesięciu lat nie tylko rozwinął się sam język tworzenia stron internetowych i ich struktura, ale także przeglądarki. Dzięki temu, dzisiaj strony internetowe są niesamowicie interaktywne, dynamiczne i funkcjonują jako pełnoprawne programy komputerowe osadzone w świecie online, z którymi wchodzimy w interakcje poprzez przeglądarki.
Językiem, w którym powstają strony internetowe jest HTML. Nie jest to język programowania, jest to język znaczników.
Przyjrzyjmy się temu przykładowi:
See the Pen Kurs_html_1 by Fundacja (@Media30) on https://codepen.io‚>CodePen.light
<!DOCTYPE html> – dokument rozpoczyna się od takiego symbolu. Nazwa ujęta w ostre nawiasy oznacza, że mamy do czynienia ze znacznikiem. Pierwszy znacznik oznacza, że mamy do czynienia z dokumentem HTML. Taki komunikat otrzymuje przeglądarka rozpoczynając analizę dokumentu, dzięki czemu wie w jaki sposób ma wyświetlać dokument. Językiem, w którym jest zakodowany dokument jest HTML, więc przeglądarka wyświetli nasz dokument jako stronę internetową. Jak zapewne zauważyliście reszta znaczników powtarza się w naszym dokumencie np. <body> ma swój odpowiednik </body>. Pierwszy jest znacznikiem otwierającym, drugi zamykającym. Można powiedzieć, że struktura dokumentu jest hierarchiczna: każdy znacznik znajduje się w jakimś znaczniku. W naszym przykładzie w znaczniku <body> znajduje się znacznik <h1>. Pomiędzy znacznikiem otwierającym a zamykającym h1 znajduje się tekst “To moja strona internetowa”. Tekst ten wyświetlany jest w przeglądarce. Relacje tego układu hierarchicznego nazywa się często relacjami dziecko-rodzic. Znacznik znajdujący się w innym znaczniku jest jego dzieckiem.
Oczywiście, aby nasza strona stała się kolorowa i interaktywna musimy wzbogacić nasz dokument o wiele elementów i poprzez hiperłącza połączyć dodatkowe dokumenty. W trakcie rozwoju stron internetowych, oprócz języka znaczników HTML powstał język tworzenia stylu dokumentu CSS oraz język programowania Javascript, który sprawił, że przeglądarka potrafi zmieniać treści strony po kliknięciu w dany element przez użytkownika.
Dobrze, wiemy jak wyglądają współczesne strony internetowe. Sprawdźmy jak prezentują się od podszewki.
Znajdujące się w jednym folderze pliki (dokumenty HTML oraz powiązane z nimi hiperłączami inne pliki jak np. formaty .jpg) powinny zostać umieszczone na serwerze. Nasz główny plik .html, powinien mieć nazwę index.html, przeglądarka przyporządkuje wtedy nasz plik do odpowiedniej nazwy domeny.
Przeglądarka to nic innego jak program, który analizuje każdy plik osobno i wykonuje polecenia, które zawarte są w dokumencie. Jeżeli pojawia się treść w znaczniku <h1>, program “wie”, że treść znajdująca się w tym znaczniku powinna być wyświetlona w powiększonej czcionce i traktowana jako nagłówek tekstu.
Dzięki możliwościom jakie dają nam współczesne przeglądarki, możemy w każdej chwili sprawdzić jak wygląda kod źródłowy dowolnej strony internetowej. W przeglądarce Chrome można to zrobić klikając prawym przyciskiem myszki i wybierając “Wyświetl źródło strony”, możemy też wejść w menu w zakładkę “Widok”, wybierając “Programista” i kolejno “Wyświetl źródło”.
Dlaczego warto wiedzieć jak działają strony internetowe? Jak wiadomo, większość danych obecnie znajduje się w internecie. Tabele nie zawsze udostępniane są w formie ściągalnych plików, często są po prostu zamieszczone na stronie internetowej w kodzie HTML. Aby móc z nich skorzystać, musimy poznać dokładnie języki i struktury, w jakich tworzone są strony internetowe.
Wcześniej wspomnieliśmy, że stronę internetową można napisać nawet w notatniku. Zatem sprawdźmy. Wpisz podany wcześniej kod ze znacznikami do notatnika:
<!DOCTYPE html>
<html>
<body>
<h1>To moja strona internetowa</h1>
<p>Zrobiłem ją w dwie minuty</p>
</body>
</html>
Aby przeglądarka otworzyła nasz plik jako stronę internetową, musimy go zapisać z rozszerzeniem .html. Zapiszmy go więc np. jako “stronka.html”. Następnie wchodzimy do folderu z naszym plikiem i prawym przyciskiem myszy otwieramy za pomocą dowolnej przeglądarki. I tyle. Właśnie stworzyłeś swoją pierwszą stronę internetową.
Podstawy języka HTML i CSS
Jak wiadomo podstawą funkcjonowania stron internetowych jest język znaczników HTML. Poznajmy więc w szczegółach jak wygląda struktura strony internetowej i jakie są podstawowe znaczniki wykorzystywane do jej budowy.
Mamy już za sobą stworzenie pierwszej prostej strony internetowej, czyli dokumentu HTML. Dokonaliśmy tego przy pomocy tak prostego narzędzia jakim jest notatnik. Pisząc rozbudowane strony internetowe, możemy dzisiaj sobie znacząco ułatwić sobie pracę korzystając z bardziej rozbudowanych narzędzi. Na rynku istnieje wiele darmowych edytorów dla programistów, np. Brackets, Atom, Sublime Text, Notepad+, Visual Studio. My zaprezentujemy ten ostatni. Pobieramy go ze strony: https://code.visualstudio.com/download. Po instalacji, powinien pojawić się nam taki ekran.

Klikamy “New file” i możemy rozpocząć pracę w edytorze. To, co od razu rzuci się nam w oczy to podkreślanie kodu programistycznego w różnych kolorach i autouzupełnianie. O dodatkowych opcjach jakie daje Visual Studio przeczytasz na stronie internetowej edytora albo korzystając z tradycyjnej możliwości “pomoc”.
Rozpoczynając pracę nad tworzeniem strony internetowej warto stworzyć sobie osobny folder na pliki html. Będziemy tam trzymać także wszelkie inne pliki związane z naszą stroną internetową jak zdjęcia i grafiki. Po stworzeniu strony cały folder jest przenoszony na serwer i to praktycznie całe uruchamianie strony internetowej.
Układ dokumentu html
Dla naszych celów edukacyjnych nie będziemy jednak korzystać z edytora. Język html będziemy teraz omawiać przy pomocy interaktywnych okienek na stronie kursu. Jak one znalazły się na tej stronie? Otóż jest to aplikacja internetowa https://codepen.io, która umożliwia wykonywanie naszego kodu strony w przeglądarce, dzięki czemu krótkie fragmenty kodu możemy sprawdzić szybko w aplikacji. Aplikacja daje możliwość osadzenia swoich okienek na dowolnej stronie internetowej – https://codepen.io/embeds/. Skorzystaliśmy więc z takiej możliwości i dzięki temu możesz wprowadzać i i sprawdzać swoje dokumenty html bezpośrednio na stronie kursu. W takim sam sposób osadza się na stronach np. wideo z youtube’a. Jak się to odbywa technicznie? Pomiędzy odpowiednimi znacznikami należy tylko wkleić odpowiedni kod. W przypadku yt klikamy pod filmem w “share”, a następnie “embed”, z boku pojawi się kod programistyczny, który jak widzimy, ma postać kodu znajdującego się między znacznikami html <iframe>…kod</iframe>. Wystarczy, że nasz znacznik wraz z treścią wkleimy w odpowiednie miejsce w kodzie źródłowym naszej strony.
Wróćmy do naszego przykładu. Wpisz wcześniejszy kod w okienku poniżej.
See the Pen Kurs_html_1 by Fundacja (@Media30) on https://codepen.io‚>CodePen.light
Tak jak już wspomnieliśmy, jest to bardzo prosty dokument html. Dokument html strony głównej posiada jeszcze inne dodatkowe znaczniki. Poznajmy zatem jak wygląda struktura typowego dokumentu html strony internetowej. Zerknijmy na poniższy kod:
See the Pen Kurs_html_2 by Fundacja (@Media30) on https://codepen.io‚>CodePen.light
Pierwszym znacznikiem jest <!DOCTYPE html>, który mówi przeglądarce, że mamy do czynienia z dokumentem z kodem html. Cała reszta naszego kodu znajduje się w znaczniku <html></html>. Następnie mamy dwa stałe elementy: <head> i <body>. W znaczniku <head>, który jest nagłówkiem naszego dokumentu, znajdują się kolejne znaczniki, w których zawarte są takie informacje jak tytuł strony w znaczniku <title>. Tytuł strony wyświetla się np. na nazwie zakładki w przeglądarce. Następnie mamy znaczniki <meta>. Widzimy tutaj małą zmianę, tym razem dodatkowa treść znajduje się w samym znaczniku. Z taką sytuacją mamy do czynienia także w wielu innych znacznikach związanych z widokiem naszej strony. Pora przyjrzeć się dokładnie jak wygląda struktura znacznika i jakie informacje ze sobą niesie.
<znacznik atrybut=”wartość atrybutu”>zawartość znacznika</znacznik>
Jak widzimy po nazwie znacznika w pierwszych ostrych nawiasach mamy nowy element, a mianowicie atrybut wraz z jego przypisaną wartością. W przypadku znacznika meta, mamy atrybut charset, który służy do określania kodowania znaków całej strony internetowej. W naszym przypadku system kodowania to UTF-8. W kolejnym znaczniku <meta> atrybut description to opis strony, który wyświetla się pod tytułem w wynikach wyszukiwania. Nie wpływa on bezpośrednio na pozycje wyszukiwania, ale interesujący opis jest w stanie wyróżnić serwis wśród wielu podobnych, a tym samym skłonić użytkownika do kliknięcia właśnie w wynik naszej strony internetowej.
W sekcji <head> w stronach internetowych znajdziemy jeszcze inne znaczniki. Wszystkie umieszczone tam elementy nie są widoczne na stronie internetowej, sprawdzić je możemy jedynie za pomocą wyświetlenia kodu źródłowego. Miejscem, gdzie znajdują się wszystkie elementy widoczne na naszej stronie to sekcja <body>. W tym znaczniku można powiedzieć znajduje się nasza właściwa strona internetowa. Jest to tzw. ciało naszej strony internetowej. W naszym prostym przykładzie w sekcji <body> mamy umieszczony sformatowany tekst. Znacznik <h1> to nagłowek pierwszego stopnia, do dyspozycji mamy jeszcze <h2> czy <h3>, wszystkie one różnią się między sobą rozmiarem czcionki. Następnym znacznikiem jest <p>, czyli paragraf. W nim umieszczamy właściwy tekst. Jeden wyraz znajduje się w znaczniku “<em>moich</em>”. <em>, czyli emphasize – podkreślenie, uwypuklenie. Element html, którego używamy jeśli chcemy uwypuklić, podkreślić znaczenie pewnego wyrazu. Efektem zastowowania tego elementu jest pochylona czcionka. Kolejnym znacznikiem jest <strong>. To znacznik, za pomocą, którego możemy nadać większe znaczenie określonemu wyrazowi, bądź wyrażeniu. Efektem zastowowania tego elementu jest pogrubiona czcionka.
Wreszcie mamy znacznik “<a href=”http://www.google.com„>Google</a>”. Znacznik <a> jest bardzo istotny w dokumencie html, ponieważ poprzez niego realizowana jest idea hipertekstualności. Znacznik ten linkuje do innych elementów na stronie lub do zewnętrznych dokumentów html czy stron internetowych. Poprzez atrybut href linkujemy do odpowiedniego adresu. W naszym przypadku jeżeli klikniemy w nazwę znajdującą się pomiędzy znacznikami <a></a>, zostaniemy przeniesieni do strony internetowej google.com (nasze internetowe okienko nie otworzy tej strony, dlatego musimy kliknąć prawym przyciskiem myszy i otworzyć w nowej karcie).
Tak właśnie wygląda struktura dokumentu html. Oczywiście, do stworzenia atrakcyjnej i interaktywnej strony internetowej, mamy do dyspozycji o wiele więcej znaczników. Większość z tych najważniejszych poznamy w tym kursie.
Tworzymy artykuł (ze zdjęciem)
Aby poznać najważniejsze znaczniki związane z treściami udostępnianymi na stronach internetowych, sami spróbujemy stworzyć typowy artykuł ze zdjęciem/grafiką, który udostępniany jest na większości stron internetowych.
W którym miejscu kodu źródłowego umieścimy nasz artykuł? Oczywiście w ciele strony, czyli znaczniku <body>
See the Pen Kurs_html_3 by Fundacja (@Media30) on https://codepen.io‚>CodePen.light
Artykuł znajduje się w znaczniku <article>. Każdy artykuł składa się z nagłówka i akapitów stanowiących jego treść. Za nagłówek odpowiada znacznik <header>. W nagłówku powinien znaleźć się z pewnością tytuł, ale można także dodać nazwisko autora. Mamy więc strukturę:
<article>
<header>
</header>
</article>
W naszym nagłówku tytuł powinien się znaleźć, w którymś z nagłówkowych znaczników np. <h1>, podpis możemy umieścić w znaczniku <p>. Dodajmy zatem tytuł: “Spadła liczba urodzeń” oraz autora: “Autor: Jan Kowalski”.
See the Pen Kurs_html_3_1 by Fundacja (@Media30) on CodePen.light
Do naszego artykułu musimy oczywiście dodać właściwą treść. Tekst naszego artykułu umieszczamy pod znacznikiem <header>, oczywiście w znaczniku <article>. W jaki sposób umieścimy nasz tekst w artykule? Wykorzystamy poznany już wcześniej znacznik <p>, w którym będziemy umieszczać każdy nowy akapit. Wpiszmy przykładowy tekst: “Połowa państw na świecie przeżywa kryzys demograficzny – rodzi się w nich niewystarczająca liczba dzieci, aby utrzymać zastępowalność pokoleń. Spadek liczby urodzeń ma więc już charakter globalny. Naukowcy przyznają, że wyniki opublikowanych w piśmie „The Lancet” badań to także dla nich wielkie zaskoczenie.” pochodzący ze strony polityka.pl – https://www.polityka.pl/tygodnikpolityka/spoleczenstwo/1771098,1,globalny-spadek-urodzen-to-efekt-cywilizacyjnego-sukcesu.read. Korzystając z przedruku z innej strony (do innych celów niż edukacyjne nie polecamy takiej praktyki) powinniśmy podać źródło. Wykorzystamy do tego kolejny znacznik <p> oraz <a>. Wpiszmy zatem nasze informacje do kodu źródłowego tak, że po kliknięciu w tekst: “Źródło: polityka.pl”, zostaniemy przeniesieni do odpowiedniej strony. Mamy już podstawowe elementy materiału dziennikarskiego: tytuł i tekst. Dla zobrazowania tematu przydałaby się jakaś grafika. Aby umieścić element graficzny na stronie internetowej trzeba wykorzystać znacznik <img> i jego atrybuty. W znaczniku <img> nie będziemy niczego wyświetlać, dlatego znacznik ten nie ma odpowiednika zamkniętego.
Aby umieścić na stronie grafikę, musimy w kodzie napisać następujący kod:
<img src=”https://galeria.bankier.pl/p/6/8/ad3ae557f31c43-645-355-0-0-872-481.png” alt=”Grafika przedstawiająca spadek urodzeń”>
src – to adres/źródło, pod którym znajduje się nasz obrazek. Może to być zewnętrzny adres url, lub umieszczona grafika w folderze naszej strony (wtedy wpiszemy w src po prostu nazwę pliku np. “zdjecie.jpg”, natomiast jeżeli zdjęcie znajduje się w podfolderze, wówczas wpiszemy: nazwa_folderu/zdjecie.jpg).
alt – to atrybut, w którym umieszczamy tekst zastępczy do naszej grafiki. Będzie on wczytany przez przeglądarkę, jeżeli nie będzie ona w stanie wyświetlić grafiki (np. z powodu niskiej jakości połączenia internetowego). Alt odczytywany jest także przez programy asystujące osobom niedowidzącym i niewidomym, dlatego programista powienien zadbać, aby atrybut nie pozostał pusty).
Umieśćmy zatem naszą grafikę pod naszym ostatnim znacznikiem <p>.
See the Pen Kurs_html_3_2 by Fundacja (@Media30) on CodePen.light
Stylujemy nasz artykuł
Nasz artykuł wygląda już obiecująco. Ma tytuł, treść i obrazującą wizualizację. Nie da się ukryć jednak, że artykuły na serwisach internetowych wyglądają o wiele bardziej przyciągająco: są kolorowe i poukładane. Aby treść na stronie internetowej była odpowiednio ułożona, tekst miał odpowiednią czcionkę, między tekstem a obrazkiem pojawiła się kolorowa linia oddzielająca, musimy skorzystać z kolejnego prostego języka jakim jest CSS. Jednym słowem służy on do nadawania odpowiedniego stylu naszym elementom. Ostylowanie umieszcza się w osobnym pliku np. o nazwie main.css. Aby nasz dokument html mógł się skomunikować z innym plikiem skorzystamy z możliwości jakie daje hipertekstualność. W znaczniku <head> oprócz znaczników <meta> dodamy następujący: <link rel=”stylesheet” href=”main.css”>. Atrybut rel dla znacznika <link> z wartością stylesheet oznacza, że mamy do czynienia z arkuszem stylów, zaś do naszego pliku (znajdującego się w naszym głównym folderze) odwołujemy się poprzez atrybut href, który już poznaliśmy przy okazji linkowania na stronie internetowej. Aby stylować stronę, musimy więc stworzyć nowy pusty plik i dać mu rozszerzenie .css. Nasze interaktywne okienka dają nam jednak możliwość wpisywania bezpośrednio kodu stylującego.
W drugim okienku, gdzie widnieje napis CSS, wpiszmy:
h1 {
color: blue;
}
Jak widać, nasz tytuł zmienił kolor na niebieski. Tak właśnie działa język css. Najpierw wpisujemy element, któremu chcemy nadać jakiś styl np. h1. Następnie w nawiasie “wąsatym” wypisujemy właściwości i ich wartości po dwukropku. Po każdym elemencie właściwości musimy postawić średnik. Element h1, który w kodzie hml jest znacznikiem, w css nazywany jest selektorem.
W pliku css wpisaliśmy po prostu h1. Jeżeli na stronie mamy wiele znaczników <h1>, przeglądarka, która będzie analizować nasz plik css, nie może i nie będzie wiedzieć o jaki element h1 nam chodzi. Wpisaliśmy przecież po prostu h1, co oznacza, że color: blue dotyczyć będzie wszystkich znaczników <h1>. W naszym artykule mamy np. kilka znaczników <p>. Chcielibyśmy zaś zmienić kolor tła nazwiska autora. Jak możemy to zrobić? Język css umożliwia sprecyzowanie znacznika, o który nam chodzi. Do tego celu wykorzystuje się hierarchiczność dokumentu html. Jeżeli chodzi nam o znacznik <p> znajdujący się w znaczniku <header>, jego ścieżka może wyglądać następująco:
article header p – program przeglądarki wchodząc do dokumentu html i sprawdzając co znajduje się w body, natrafia na znacznik <article>. Nasz tekst, który chcemy ostylować znajduje się w znaczniku <header>, ten z kolei znajduje się w znaczniku <article>. Powyżej article nie ma już żadnych znaczników rodziców, jest tylko <body>. W pliku css ostylowanie tego paragrafu będzie wyglądać następująco:
article header p {
background-color: grey;
color: white;
}
background-color – czyli ustawiamy kolor tła naszego paragrafu
color – tutaj ustawiamy kolor tekstu znajdującego się w paragrafie.
To co sprawia, że stylowanie jest takie inspirujące, to możliwość stylowania konkretnych elementów przez wiele selektorów, ale także stylowania wielu elementów przez jeden selektor. Chcąc np. wyśrodkować naszą grafikę, znacznikowi img możemy przyporządkować atrybut w postaci klasy i nadać mu wartość np.
<img src=”https://galeria.bankier.pl/p/6/8/ad3ae557f31c43-645-355-0-0-872-481.png” class=”center” alt=”Grafika przedstawiająca spadek urodzeń”>
W pliku css wykorzystamy klasę, przyporządkowując wartości center odpowiednie właściwości.
.center {
display: block;
margin-left: auto;
margin-right: auto;
}
Zobaczmy jak wykorzystuje się selektor klasy. Selektorem klasy jest wartość atrybutu “class”. W naszym przypadku chodzi nam o wartość “center”. W pliku css selektor ten rozpoczynamy kropką “.center”, następnie tak jak wcześniej stylujemy poprzez ustawianie odpowiednich właściwości selektora.
display: block – oznacza nic innego jak to, że nasz element traktowany jest jako blok. Nie będziemy się tutaj rozwodzić nad konkretnym zastosowaniem tej właściwości, wystarczy, że powiemy, że odnosi się on do sposobu układania się elementu html względem sąsiadujących elementów html lub tekstu.
margin-left: auto;
margin-right: auto – sprawia, że nasz element ma równe marginesy z każdej strony i finalnie zawsze znajduje się na środku.
Oczywiście możliwości stylowania strony internetowej jest wiele. Skoncentrowaliśmy się tylko na ogólnych zasadach działania języka css. Przeglądając kod źródłowy danej strony ostylowanie możemy znaleźć zarówno w osobnym pliku css, ale także bezpośrednio w kodzie html. Takie rozwiązanie umożliwia użycie atrybutu “style” np. <p style=”background-color: grey”>Autor: Jan Kowalski<p>. Podsumowując, w taki sposób udostępniane są materiały informacyjne na stronach internetowych. W internecie możemy się jednak natknąć nie tylko na materiały informacyjne czy na pliki do pobrania, ale także na dane osadzone w samym dokumencie html. Np. aby umieścić na stronie dane tabelaryczne wykorzystuje się znaczniki tabeli. Jako przykład jak wyglądają takie fragmenty stron wykorzystamy podstronę http://statystyka.policja.pl/ Komendy Głównej Policji, gdzie stron z osadzonymi danymi znajdziemy bardzo dużo (to kolejny przykład niewłaściwego udostępniania danych przez instytucję publiczną, z danymi można się zapoznać na stronie internetowej, albo pobrać w formie pliku pdf). Mamy więc stronę http://statystyka.policja.pl/st/wybrane-statystyki/bron/bron-pozwolenia/50886,Bron-pozwolenia-2017.html ze statystykami ukazującymi liczbę wydanych pozwoleń na broń do roku 2017. Korzystając z możliwości sprawdzenia kodu źródłowego w przeglądarce, możemy skopiować fragment kodu, w którym znajdują się tabelę. Fragment ten rozpoznamy po znaczniku <table> (w przeglądarce Chrome klikamy prawym przyciskiem myszy i wybieramy “Wyświetl źródło strony” następnie kombinacją ctr+f wyszukujemy nazwę “<table>”). Kod tabeli możecie sprawdzić poniżej:
See the Pen Kurs_html_4 by Fundacja (@Media30) on CodePen.light
Zacznijmy od podstawowej struktury i znaczników tabeli. Tabele tworzymy przy użyciu elementu <table>. Wiersze do tabeli dodajemy poprzez element <tr> (ang. table row – wiersz tabeli). Aby tabela poprawnie wyświetlała dane, należy dodać do niej komórki. Komórki tabeli dodajemy poprzez element <td> (ang. table data – dane tabeli). Treści umieszczamy zawsze w znaczniku <td>. Element ten podobny jest nieco do kolumny. Za każdym razem musimy dodać tyle komórek (kolumn) do wiersza, ile aktualnie nam potrzeba.
<table>
<tr>
<td>1 wiersz 1 kolumna</td>
<td>1 wiersz 2 kolumna</td>
</tr>
<tr>
<td>2 wiersz 1 kolumna</td>
<td>2 wiersz 2 kolumna</td>
</tr>
</table>
Nagłówek uzyskujemy poprzez element <th> (ang. table heading). Znacznik ten stosujemy tak jak zwykłą komórkę tabeli, czyli <td>. Nagłówki także umieszczamy w wierszach tabeli, czyli elementach <tr>. Obszar nagłówkowy zamykamy w znaczniku <thead>, zaś właściwą część tabeli określamy elementem <tbody>. Z kolei znacznik <caption> stwarza możliwość nadania tytułu w formie nagłówka nad bądź podpisu pod tabelą, który może być umiejscowiony na górze (domyślnie) lub na dole tabeli.
<table>
<caption>Liczba osób którym wydano pozwolenie na broń</caption>
<thead>
<tr>
<th>Nagłówek kolumny</th>
</tr>
<tr>
<td>wiersz</td>
</tr>
</thead>
<tbody>
<tr>
<td>1 wiersz 1 kolumna</td>
<td>1 wiersz 2 kolumna</td>
</tr>
</tbody>
</table>
Jak widać, znaczniki tabeli z naszego przykładu zawierają jeszcze wiele atrybutów jak np. cellpadding, cellspacing. Jak wiele elementów strony internetowej, także tabelę można stylować na wiele sposobów. Możemy ustalać grubość linii, wielkość komórek etc. Sposoby stylowania tabel można znaleźć w wielu poradnikach w internecie. Z kolei atrybut “scope”, który nie dotyczy stylowania tabeli, określa ustawienie komórek danych, dla których aktualna komórka nagłówkowa (th) dostarcza informacji nagłówkowej, np. col – aktualna komórka dostarcza informacji nagłówkowej dla reszty kolumny, która ją zawiera. Poznanie struktury i znaczników tabeli z pewnością przyda się przy pracy z osadzonymi danymi tabelarycznymi na stronach internetowych.
Blokowa struktura strony
Tak jak patrząc się na pierwszą stronę gazety, tak też na stronie internetowej dostrzeżemy powiązane ze sobą blokowe elementy. Mamy więc nagłówek, stopkę, panel boczny, etc. Elementy strony internetowej są umieszczone względem siebie z boku, na górze, na dole. Sposób ich wyświetlania i ułożenie ustala się przede wszystkim za pomocą języka css. W kodzie html możemy jedynie dostrzec ich listę ułożoną jeden pod drugim lub zgodnie z zasadami hierarchii znajdziemy oczywiście elementy osadzone i innych elementach. W blokach html możemy umieścić np. panel reklamowy, artykuł prasowy, menu czy stopkę kontaktową. Elementy strony internetowej tworzą znaczniki <div> i <span>. <div> to element blokowy naszej strony internetowej, tzn. jeżeli takie elementy są wypisane jeden za drugim, zostaną wyświetlone w nowych liniach na stronie internetowej. W przypadku elementu <span>, który jest liniowy, treści zawarte w takim znaczniku zostaną wyświetlone w jednej linii, np. tekst <span>To jest<span>przykładowy>tekst<span> zostanie wyświetlony w jednej linii. Zobaczmy jak tworzenie struktury strony internetowej wygląda w praktyce. Stwórzmy naszą strukturę, wpisując znaczniki do kodu źródłowego. Gdzie? Oczywiście w znaczniku <body>.
<body>
<div id=”container”>
<div id=”logo”>
</div>
<div id=”nav”>
</div>
<div id=”content”>
</div>
<div id=”aside”>
</div>
<div id=”footer”>
</div>
</div>
</body>
Główne bloki strony internetowej tworzy się poprzez znaczniki <div>, aby oznaczyć, które elementy odpowiadają za dany blok, korzysta się z atrybutu “id”. Atrybut ten nadaje indywidualną nazwę danemu elementowi <div>, dzięki temu każdy element można indywidualnie stylować w pliku css. Wprowadźmy nasz kod html do okienka. W karcie css, wprowadziliśmy już ostylowanie w css.
See the Pen Kurs_html_5 by Fundacja (@Media30) on CodePen.light
Aby zwiększyć pole logo wpiszmy np. “To jest przykładowa strona” w znaczniku <h1>. Jak widzimy, nasza strona jest w tym momencie podzielona na odpowiednie bloki. Za to jak się prezentują w przeglądarce odpowiada plik css. Aby ostylować konkretny blok (<div>) w pliku css odnosimy się do niego poprzez znak # (znak # zawsze odnosi się do konkretnego id z pliku html). W kodzie strony możemy się także natknąć na semantyczne odpowiedniki znaczników <div>. Trzeba pamiętać, że zarówno język html jaki i css podlegają cały czas zmianom.
<div id=”header”> – <header>
<div id=”menu”> – <nav>
<div id=”content”> – <section>
<div class=”article”> – <article>
<div id=”footer”> – <footer>
Dogłębne omówienie języka html można znaleźć na stronie https://www.w3schools.com/html/default.asp .
Javascript
Język programowania javascript zazwyczaj znajdujący się w osobnym pliku podlinkowany hiperłączem z głównego pliku html sprawia, że nasza strona staje się interaktywna. Co dokładnie robi javascript? Np. komunikuje przeglądarce, że ma wysłać emaila z wpisaną wiadomością z formularza po tym, jak użytkownik kliknie w przycisk “wyślij”. Tak samo jak html, język javascript jest przetwarzany przez przeglądarkę (jak widzimy, obecnie przeglądarki to rozbudowane narzędzia).
Jak funkcjonuje język javascript i czym jest programowanie dowiecie się w późniejszej części kursu. Kod javascript umieszczony jest zazwyczaj w osobnym pliku z rozszerzaniem .js.
[codepen – https://www.w3schools.com/jsref/tryit.asp?filename=tryjsref_html_click]
W tym przykładzie kod javascript sprawia, że po najechaniu myszką w checkbox, zaznacza się automatycznie pole.
Link do pliku js osadza się w znaczniku <head> w następującym znaczniku:
<script type=”text/javascript” src=”plik.js”></script>
Automatyczne pobieranie danych ze stron www
Jako, że strona internetowa posiada ściśle określoną strukturę, przy pomocy bardziej zaawansowanych narzędzi możemy wydobyć w prosty sposób dane się na niej znajdujące. Program analizując kod strony internetowej dokonuje tzw. parsowania. Po przeparsowaniu strony internetowej program wie, gdzie które dokumenty znajdują się na danej stronie. Wydobycie natomiast konkretnych danych, które nas interesują dokonuje się za pomocą tzw. web scrapingu. Tego typu program może np. wydobyć informacje na temat cen produktów z portalu z ogłoszeniami i zapisać go w osobnym pliku. Przykładem takiego programu jest import.io (jeżeli chcemy zescpraować większe ilości danych, musimy wykupić opcję płatną). Czasami warto skorzystać z tego typu narzędzi, jeżeli chcemy stworzyć własną bazę danych na podstawie danych osadzonych bezpośrednio na stronie internetowej w kodzie html. Pokażemy działanie import.io na konkretnym przykładzie. Aby skorzystać z import.io należy się zarejestrować w podany na stronie startowej sposób.
Po zalogowaniu wchodzimy na “dashboard”. Następnie w lewym panelu klikamy w “Extractors”. W tym panelu będziemy scrapować wybraną stronę internetową. Klikamy w “New Extractor” i wklejamy link do strony internetowej.
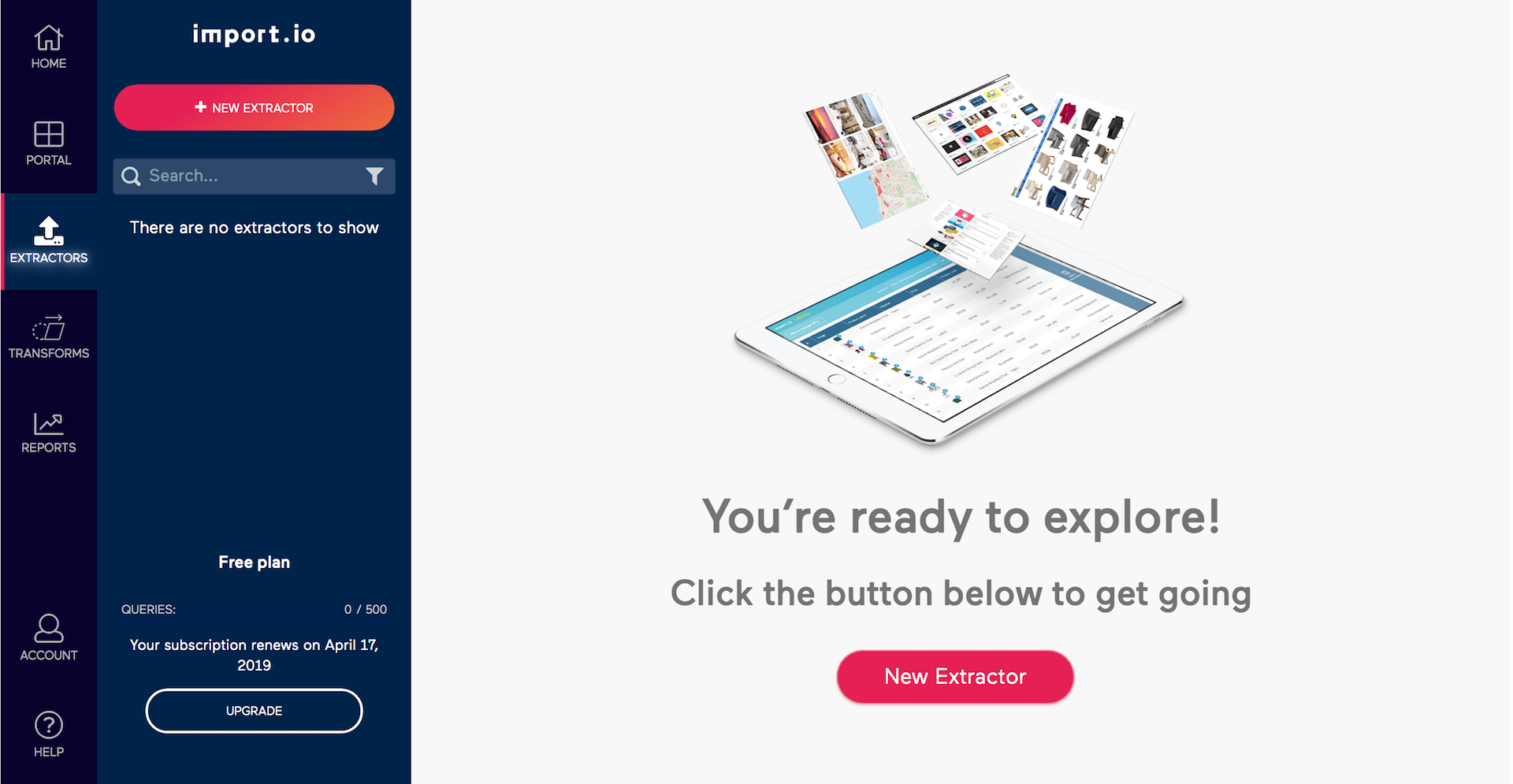
Weźmy np. stronę z listą warszawskich radnych, znajdującą się na warszawskim Biuletynie Informacji Publicznej (niestety na stronie nie znajdziemy podobnej listy w formie arkusza kalkulacyjnego). W okienko wklejamy więc adres: https://bip.warszawa.pl/Menu_podmiotowe/rada_warszawy_2018_2023/radni/default.htm. Program przeparsuje stronę internetową i pokaże nam dane, które prawdopodobnie będą idealnie nadawać się do scrapowania. W naszym przypadku jest to tabela z listą radnych Warszawy. Program w tym miejscu daje jeszcze dodatkowe możliwości edycji, jednak pominiemy je na tym etapie kursu. Jeżeli dane wydają się nam satysfakcjonujące, klikamy w przycisk znajdujący się w górnym prawym rogu “Extract data from website”. Program wykona scrapowanie strony internetowej. Co czasami może trochę potrwać. Po zakończeniu procesu, program poinformuje nas o tym i z prawej strony na pasku “Run history” pojawi się ikonka “Download Data”.

Możemy wybrać plik Excel lub CSV. Po zapisaniu pliku i otwarciu w dowolnym programie, zauważymy, że oprócz listy radnych w tabeli mamy także linki do opisów radnych ze strony Rady Miasta Stołecznego Warszawy. W ten sposób wykorzystując import.io możemy wydobyć dane z wielu stron internetowych, zwłaszcza instytucji publicznych, które bardzo często publikują różnego rodzaju listy w formie osadzonej w kodzie HTML.
W przypadku danych osadzonych na stronie internetowej w postaci tabeli (<table></table>) do ich pobrania możemy posłużyć się prostą wtyczką do przeglądarki Chrome – “Table Capture”. Po jej zainstalowaniu, wejdźmy na przykładową stronę. Dane w postaci osadzonej w formie tabel na stronie internetowej umieszcza polska Policja (niestety nie uświadczymy tych danych w formie arkuszy kalkulacyjnych do pobrania). Wybierzmy np. dane dotyczące nietrzeźwych kierowców: http://www.statystyka.policja.pl/st/wybrane-statystyki/nietrzezwi-sprawcy-prz/50862,Nietrzezwi-sprawcy-przestepstw.html. Po kliknięciu w ikonkę wtyczki pojawi się panel, w którym klikamy w zieloną ikonkę arkusza Google z prawej strony. Następnie otworzy się nam arkusz Google, w którym naciskamy po prostu CTRL+V. Możemy też kliknąć niebieską ikonkę i wkleić tabelę w dowolny arkusz kalkulacyjny. W ten sposób możemy pobrać dane w formie tabel z dowolnych stron internetowych w szybki i prosty sposób, tym samym oszczędzając czas na ręczne kopiowanie danych.
A jak przebiega scrapowanie od strony technicznej? Wyodrębnianie danych ze stron internetowych wykonuje się poprzez kawałek kodu, tzw. „skrobaka”, który wysyła zapytanie „GET” (metoda protokołu HTTP) do konkretnego adresu (URL), po czym analizuje otrzymane dane oraz wybiera istotne informacje konwertując je do określonego formatu. W ten sposób pozyskać można dane na temat wybranego produktu, obrazu, filmu, tekstu, aktualnej prognozy pogody, a nawet danych kontaktowych, jak e-mail, czy numer telefonu. W przypadku wtyczki “Table Capture” program analizuje miejsca ze znacznikami <table></table> i pobiera dane znajdujące się w poszczególnych wierszach i kolumnach.
Scrapowanie też przeprowadzić przy użyciu bardziej zaawansowanych narzędzi. Przydaje się to zwłaszcza, jeżeli chodzi nam o dane bez struktury lub większe ich liczby. Do tego celu służy np. biblioteka Beautiful Soup do języka programowania Python.
